Jing-Tong (Roger) Tzeng

I am a Master’s student at National Tsing Hua University (College of Semiconductor Research), advised by Prof. Chi-Chun (Jeremy) Lee. During my master’s studies, I also visited Prof. Carlos Busso’s Multimodal Speech Processing (MSP) Lab at The University of Texas at Dallas.
My work focuses on emotion recognition and biosignal analysis, with an emphasis on reducing aliasing introduced by front-end deep-learning preprocessing to improve downstream performance. In parallel, I develop human-in-the-loop generative components that enable targeted intervention in model outputs, increasing transparency and user trust. Broadly, I’m interested in multi-task learning and multimodal interaction.
selected publications
- arXiv
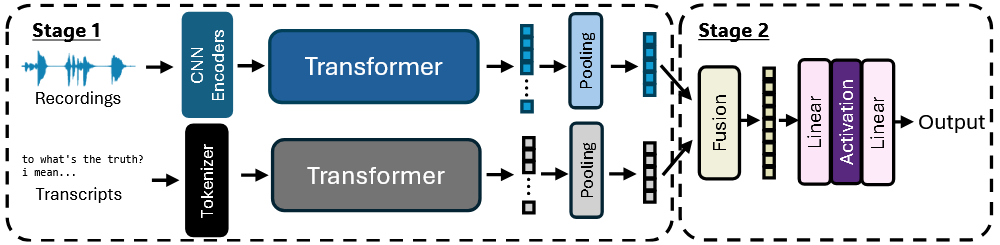
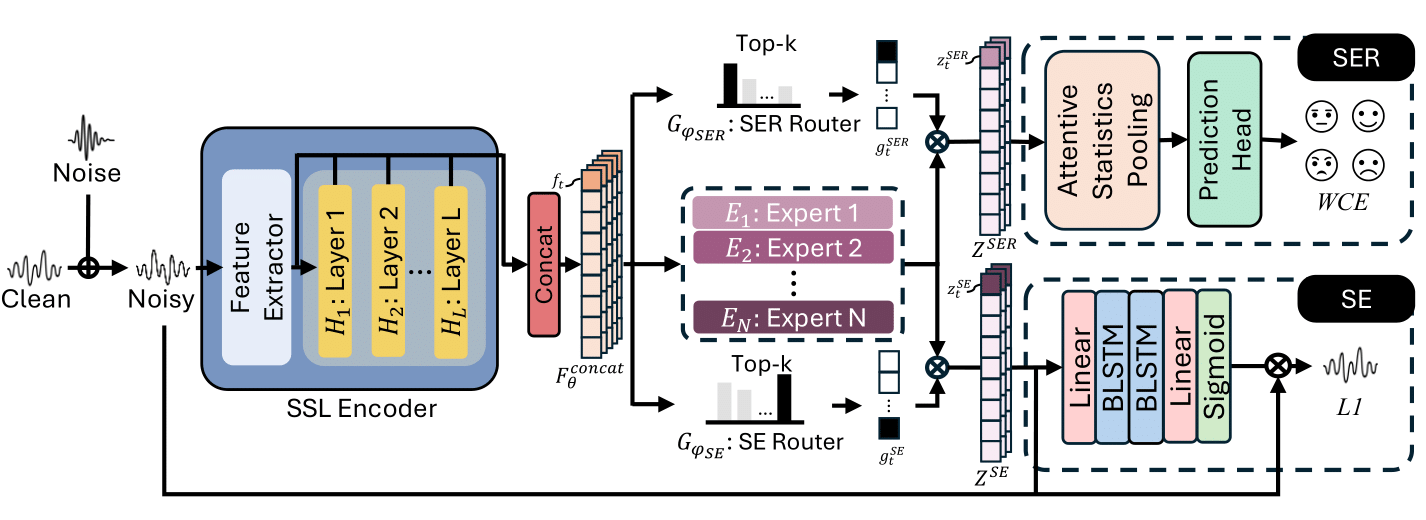 Joint Learning using Mixture-of-Expert-Based Representation for Enhanced Speech Generation and Robust Emotion RecognitionarXiv preprint arXiv:2509.08470, 2025
Joint Learning using Mixture-of-Expert-Based Representation for Enhanced Speech Generation and Robust Emotion RecognitionarXiv preprint arXiv:2509.08470, 2025 - ICASSP
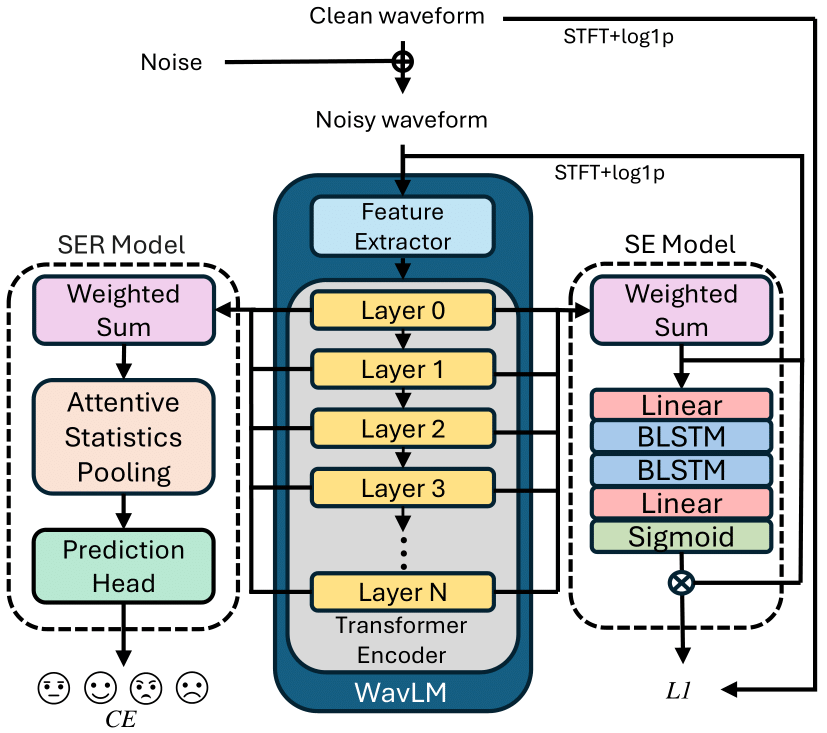 Noise-Robust Speech Emotion Recognition Using Shared Self-Supervised Representations with Integrated Speech EnhancementIn IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
Noise-Robust Speech Emotion Recognition Using Shared Self-Supervised Representations with Integrated Speech EnhancementIn IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025