This is the official demo website for “Improving the Robustness and Clinical Applicability of Automatic Respiratory Sound Classification Using Deep Learning–Based Audio Enhancement: Algorithm Development and Validation,” in JMIR AI.
Our paper: https://ai.jmir.org/2025/1/e67239/
Abstract
Background:
Deep learning techniques have shown promising results in the automatic classification of respiratory sounds. However, accurately distinguishing these sounds in real-world noisy conditions poses challenges for clinical deployment. In addition, predicting signals with only background noise could undermine user trust in the system.
Objective:
This study aimed to investigate the feasibility and effectiveness of incorporating a deep learning–based audio enhancement preprocessing step into automatic respiratory sound classification systems to improve robustness and clinical applicability.
Methods:
We conducted extensive experiments using various audio enhancement model architectures, including time-domain and time-frequency–domain approaches, in combination with multiple classification models to evaluate the effectiveness of the audio enhancement module in an automatic respiratory sound classification system. The classification performance was compared against the baseline noise injection data augmentation method. These experiments were carried out on 2 datasets: the International Conference in Biomedical and Health Informatics (ICBHI) respiratory sound dataset, which contains 5.5 hours of recordings, and the Formosa Archive of Breath Sound dataset, which comprises 14.6 hours of recordings. Furthermore, a physician validation study involving 7 senior physicians was conducted to assess the clinical utility of the system.
Results:
The integration of the audio enhancement module resulted in a 21.88% increase with P<.001 in the ICBHI classification score on the ICBHI dataset and a 4.1% improvement with P<.001 on the Formosa Archive of Breath Sound dataset in multi-class noisy scenarios. Quantitative analysis from the physician validation study revealed improvements in efficiency, diagnostic confidence, and trust during model-assisted diagnosis, with workflows that integrated enhanced audio leading to an 11.61% increase in diagnostic sensitivity and facilitating high-confidence diagnoses.
Conclusions:
Incorporating an audio enhancement algorithm significantly enhances the robustness and clinical utility of automatic respiratory sound classification systems, improving performance in noisy environments and fostering greater trust among medical professionals.
Demo
Normal:
We recommend using headphones for this section.
| Noisy | Wave-U-Net | PHASEN | MANNER | CMGAN | Target | |
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
|
| 0 |  |
 |
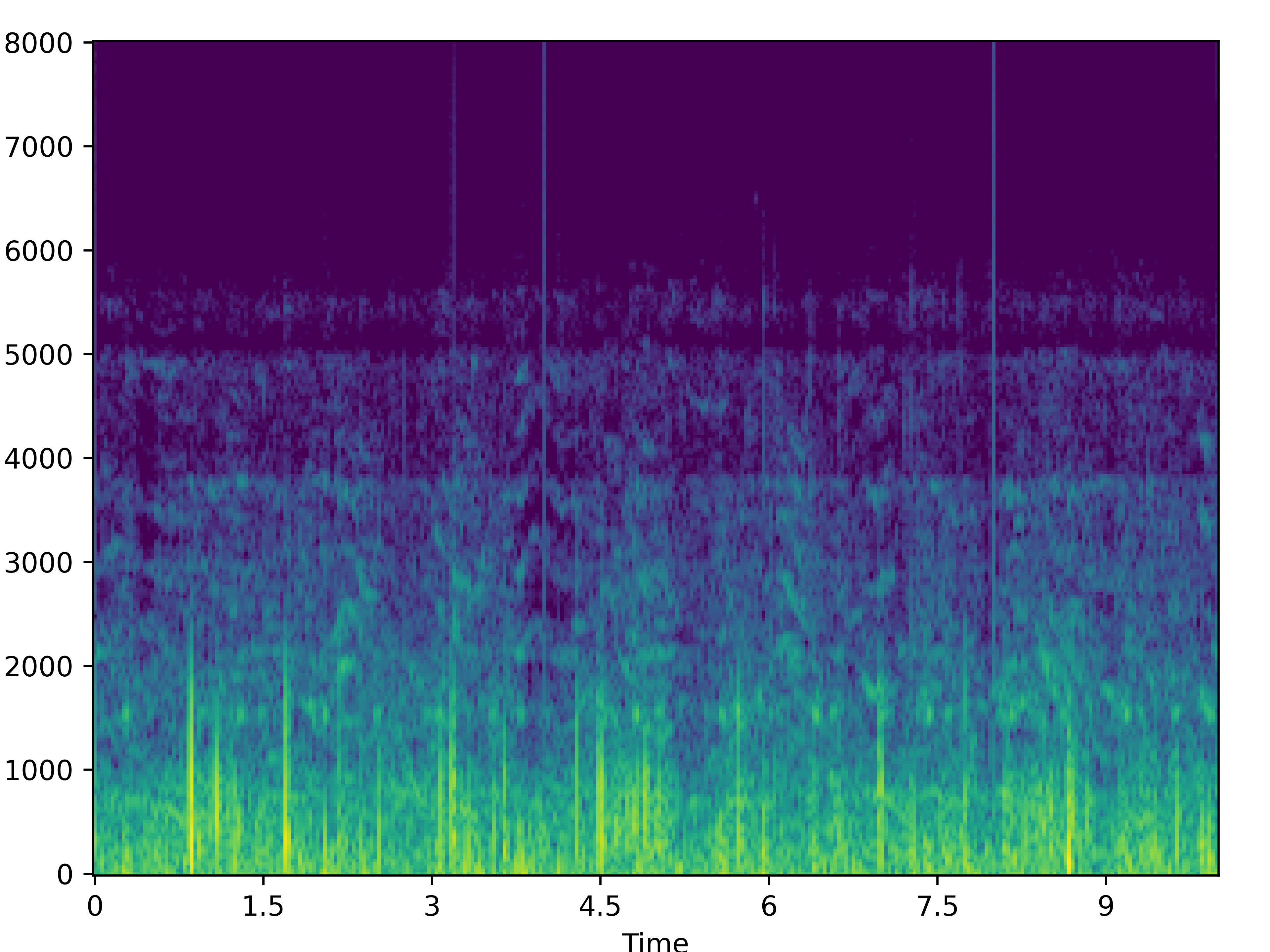 |
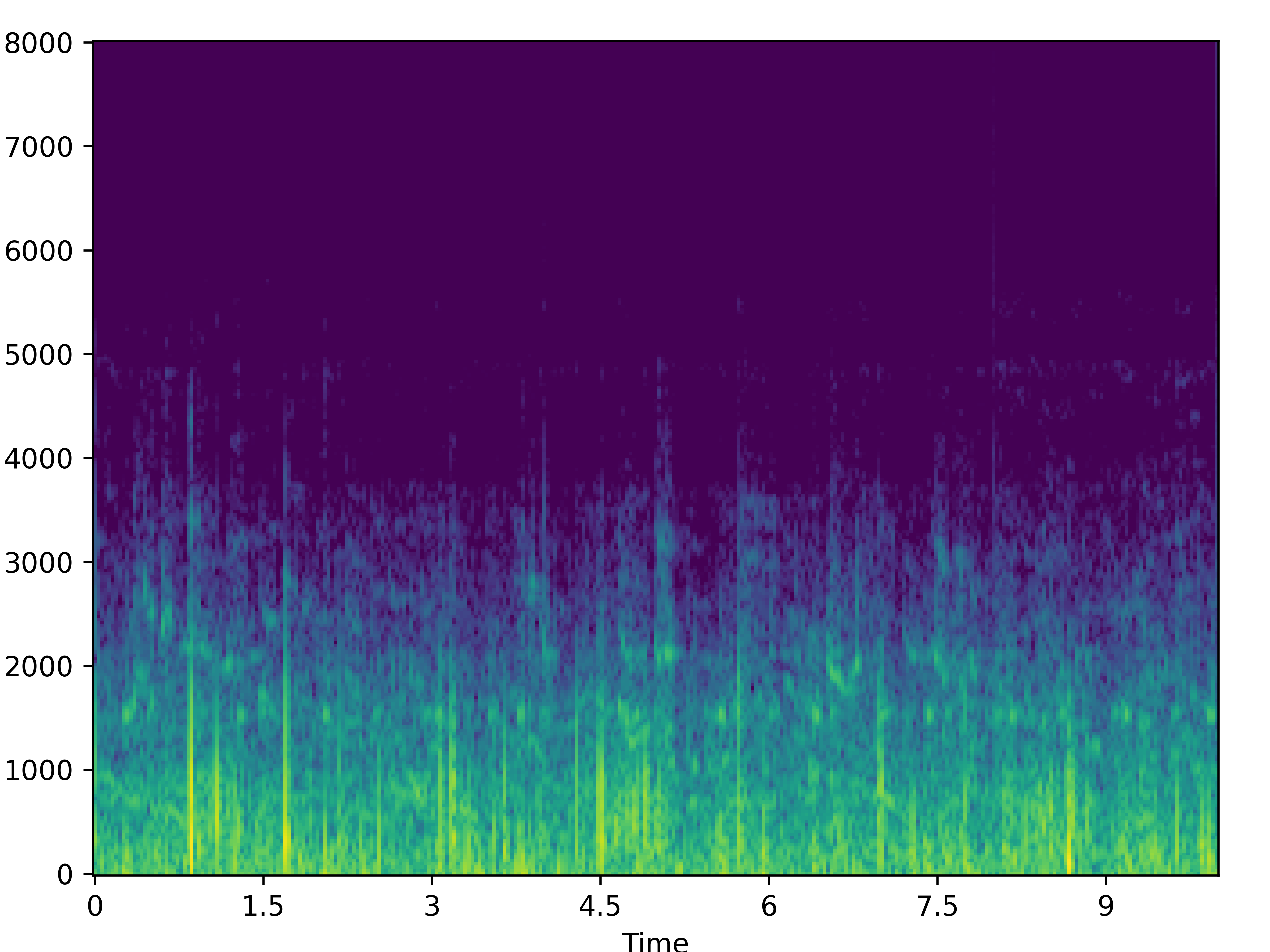 |
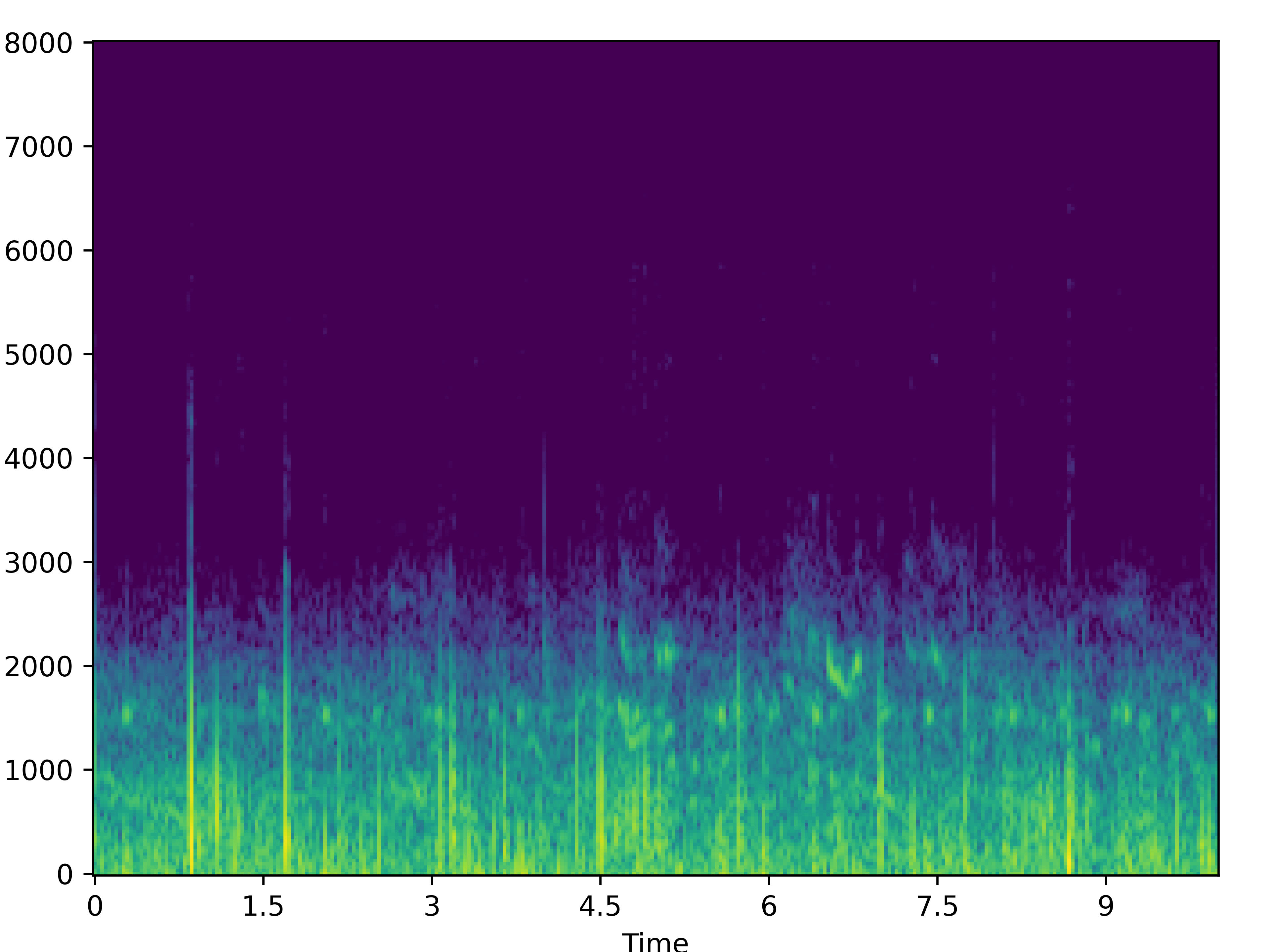 |
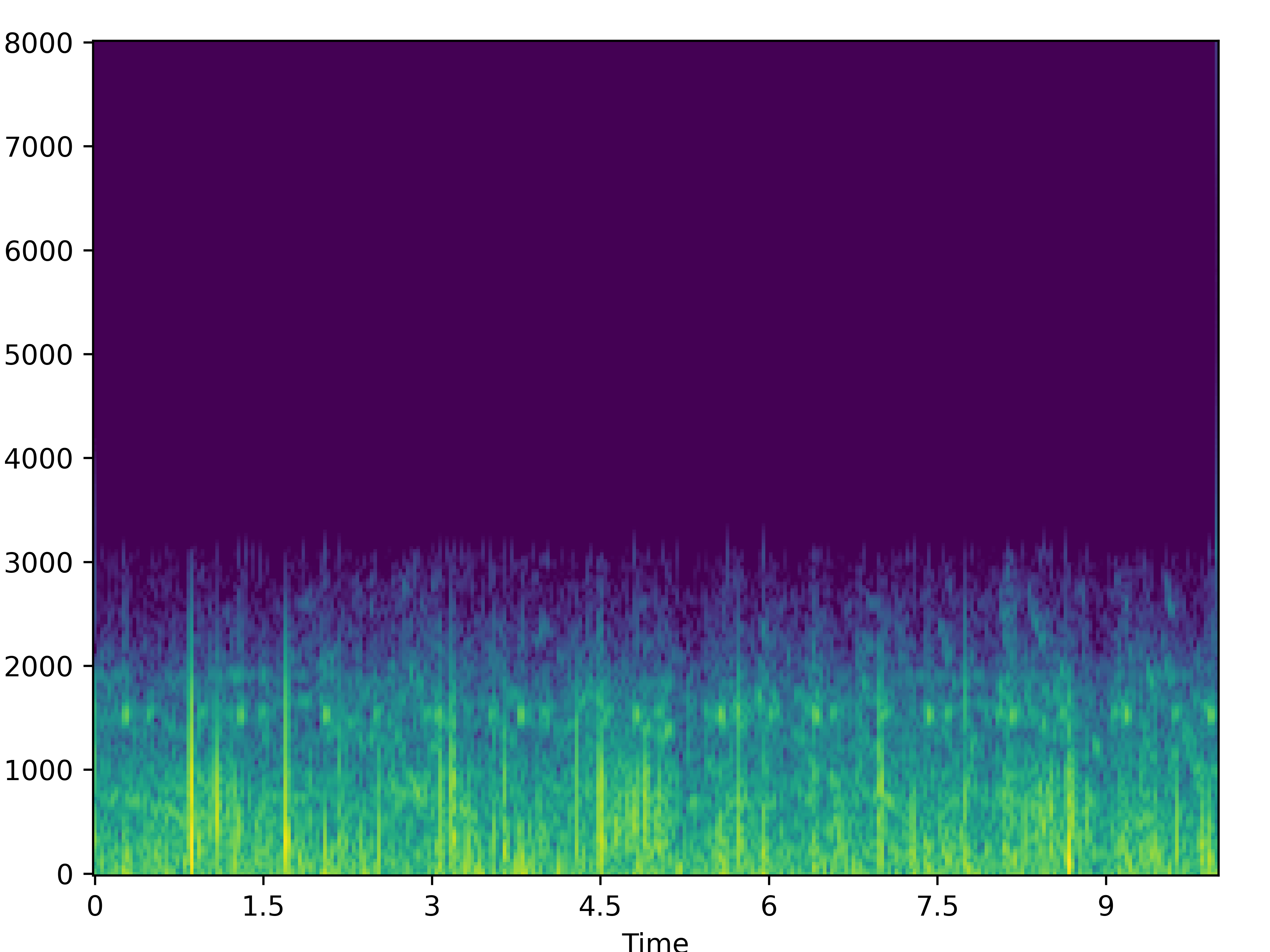 |
 |
 |
 |
 |
 |
 |
|
| 1 |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
| 2 |  |
 |
 |
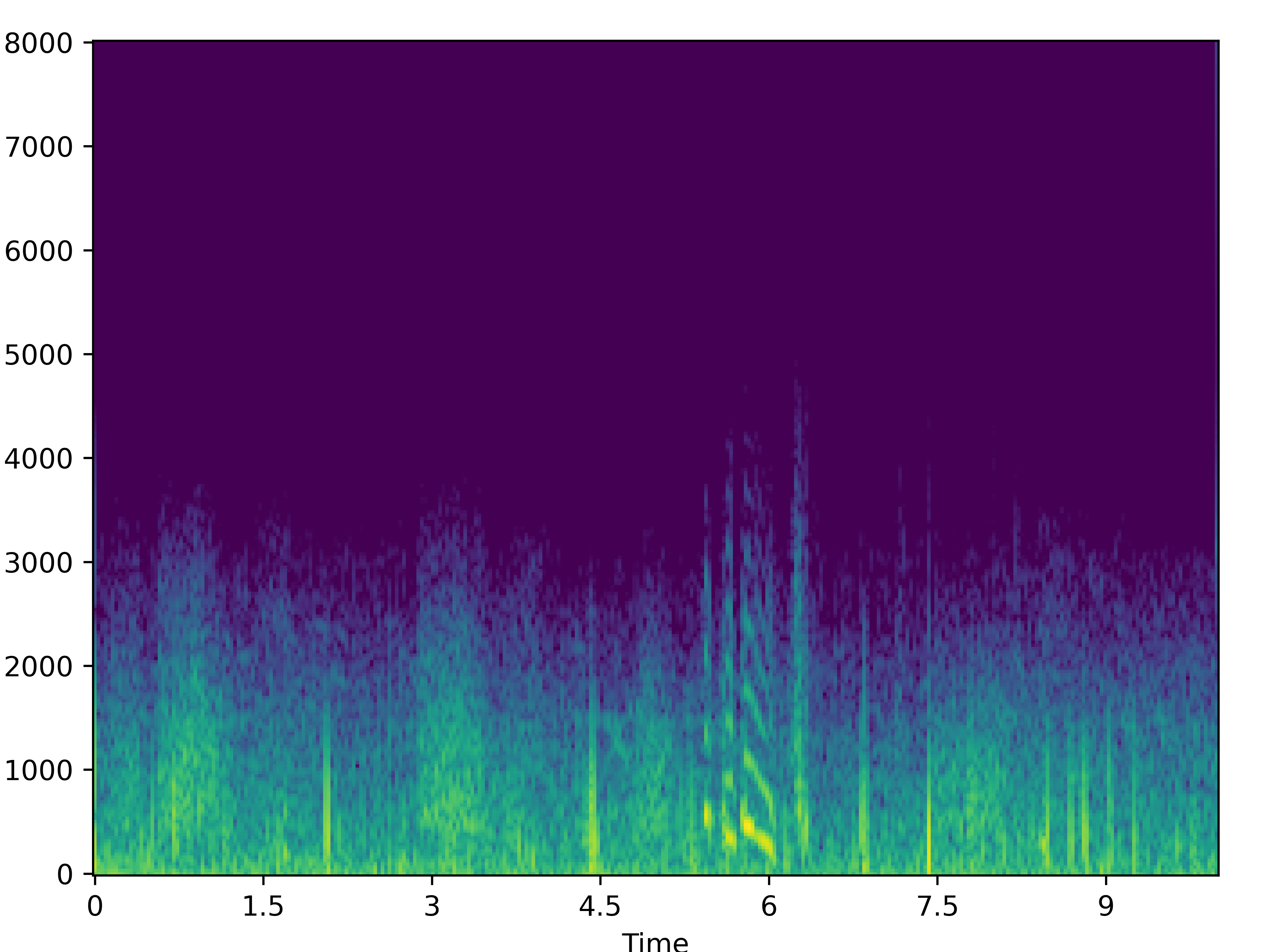 |
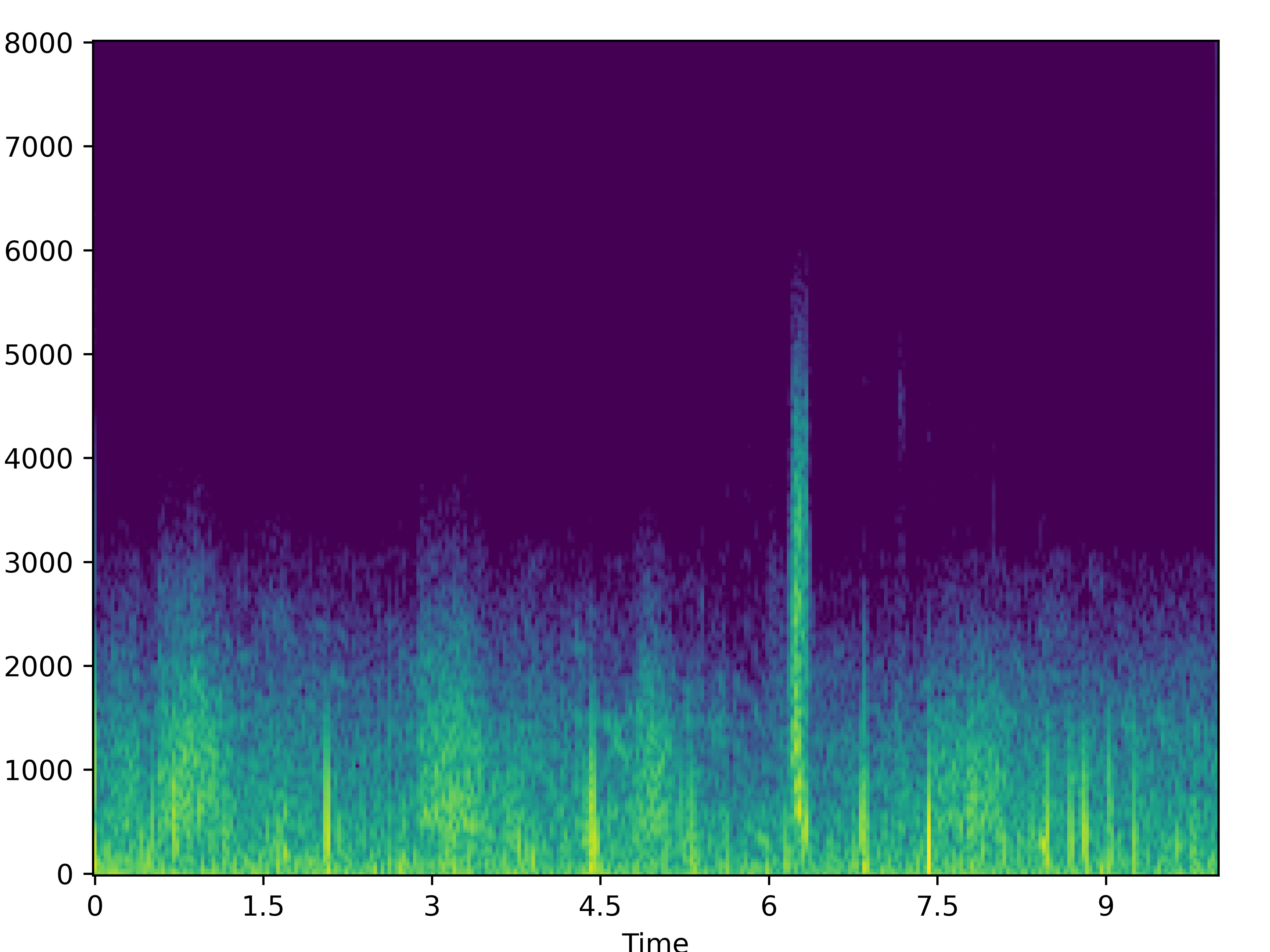 |
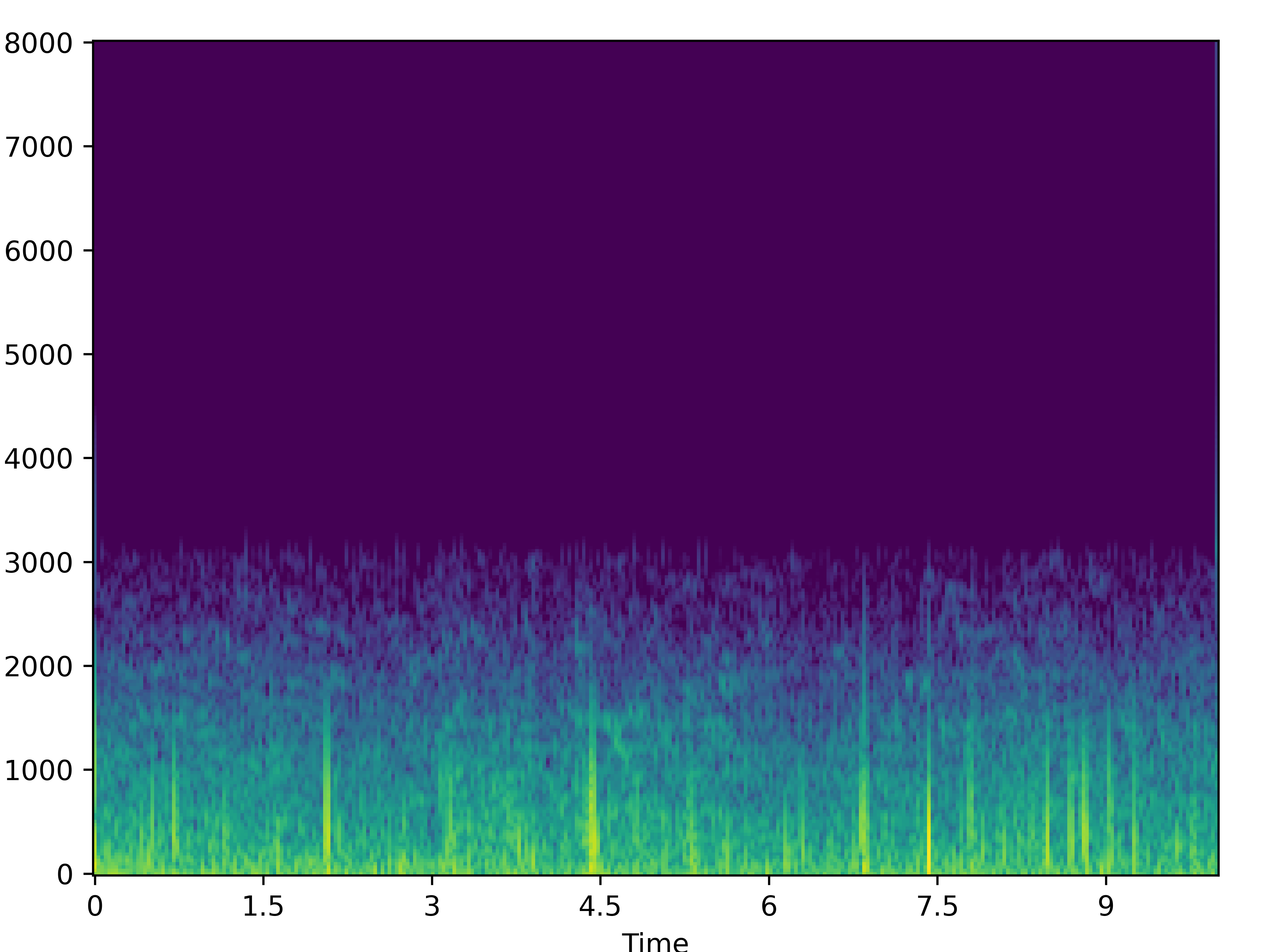 |
Crackles:
We recommend using headphones for this section.
| Noisy | Wave-U-Net | PHASEN | MANNER | CMGAN | Target | |
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
|
| 0 |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
| 1 |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
| 2 |  |
 |
 |
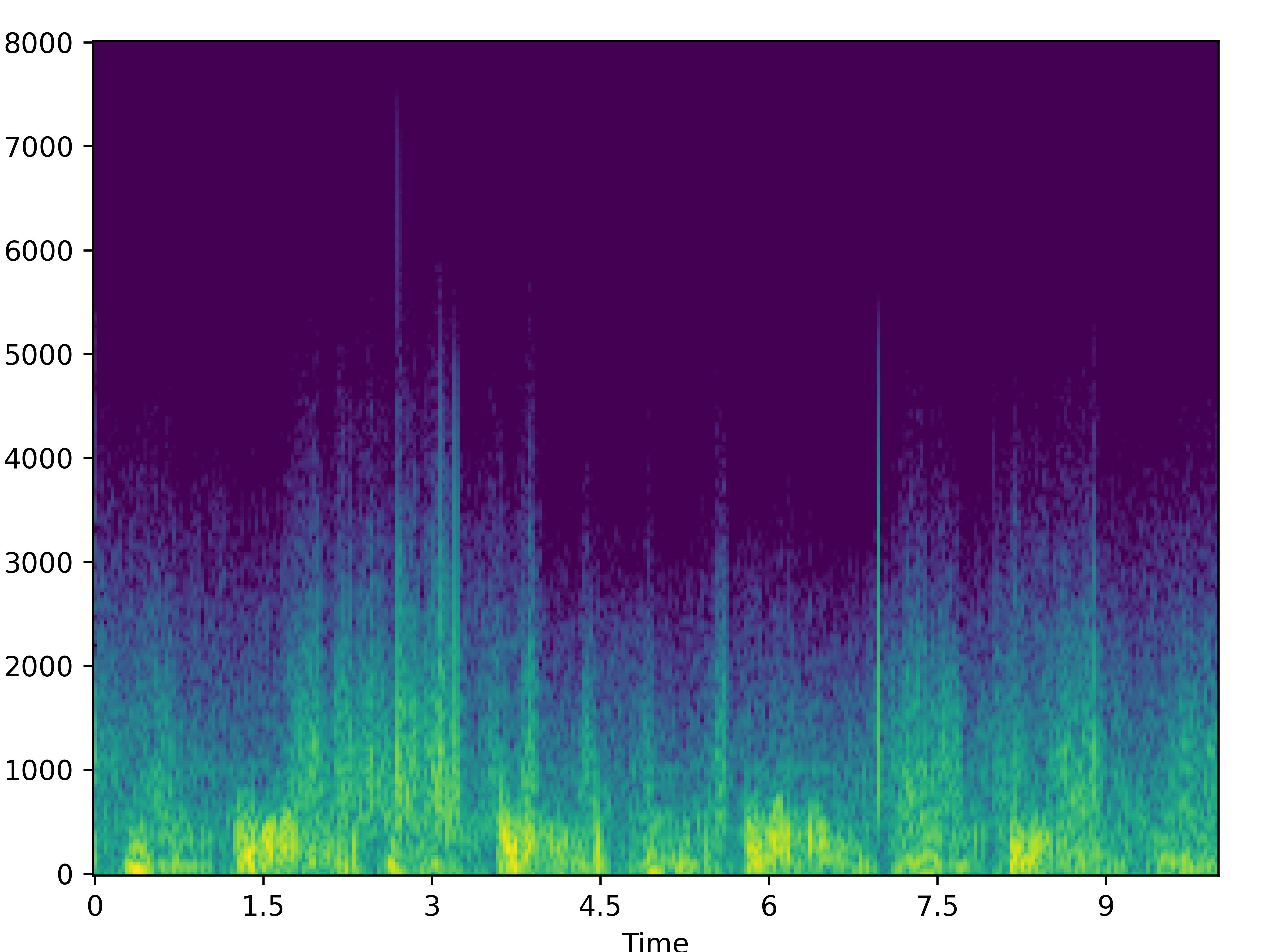 |
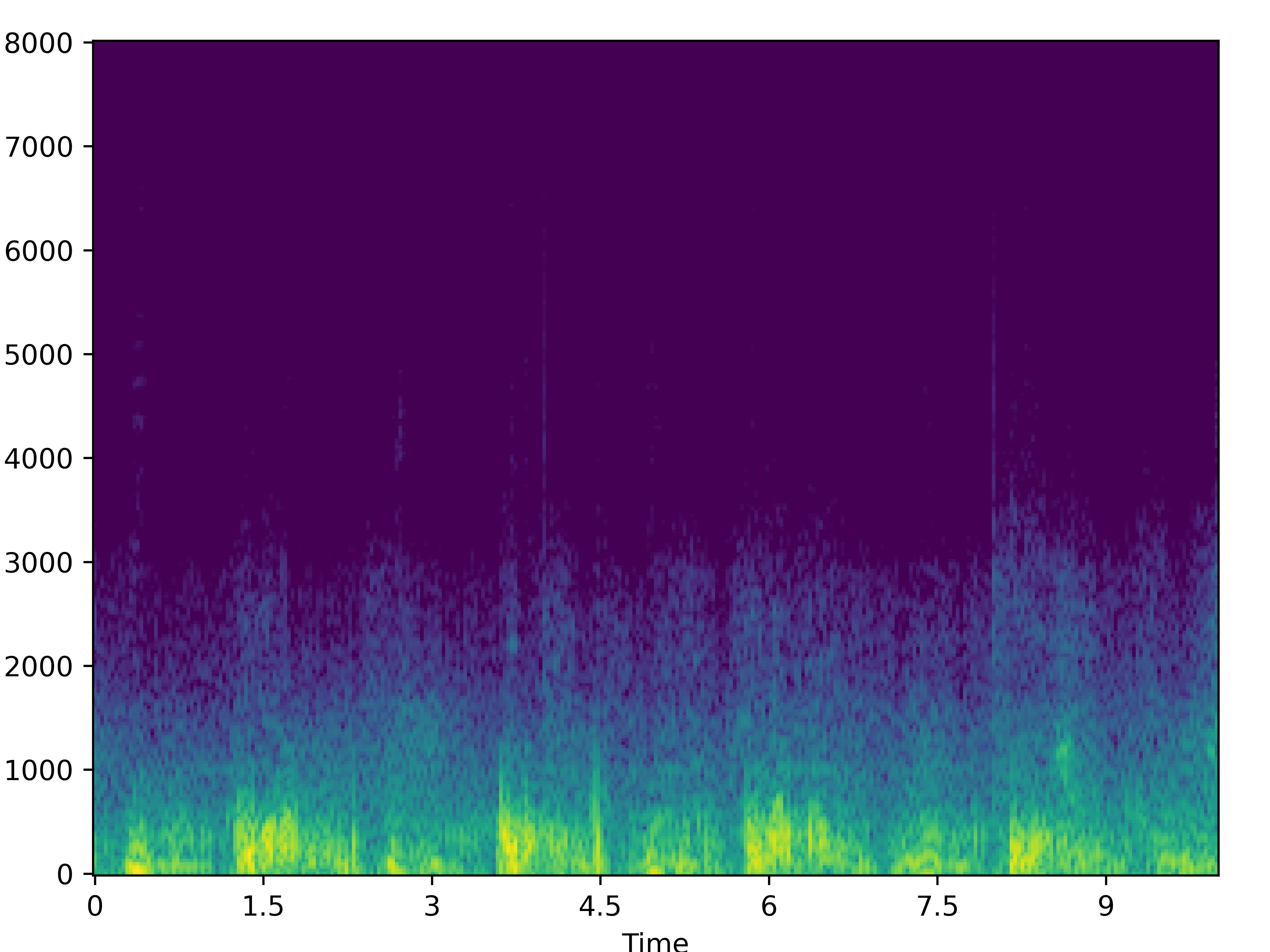 |
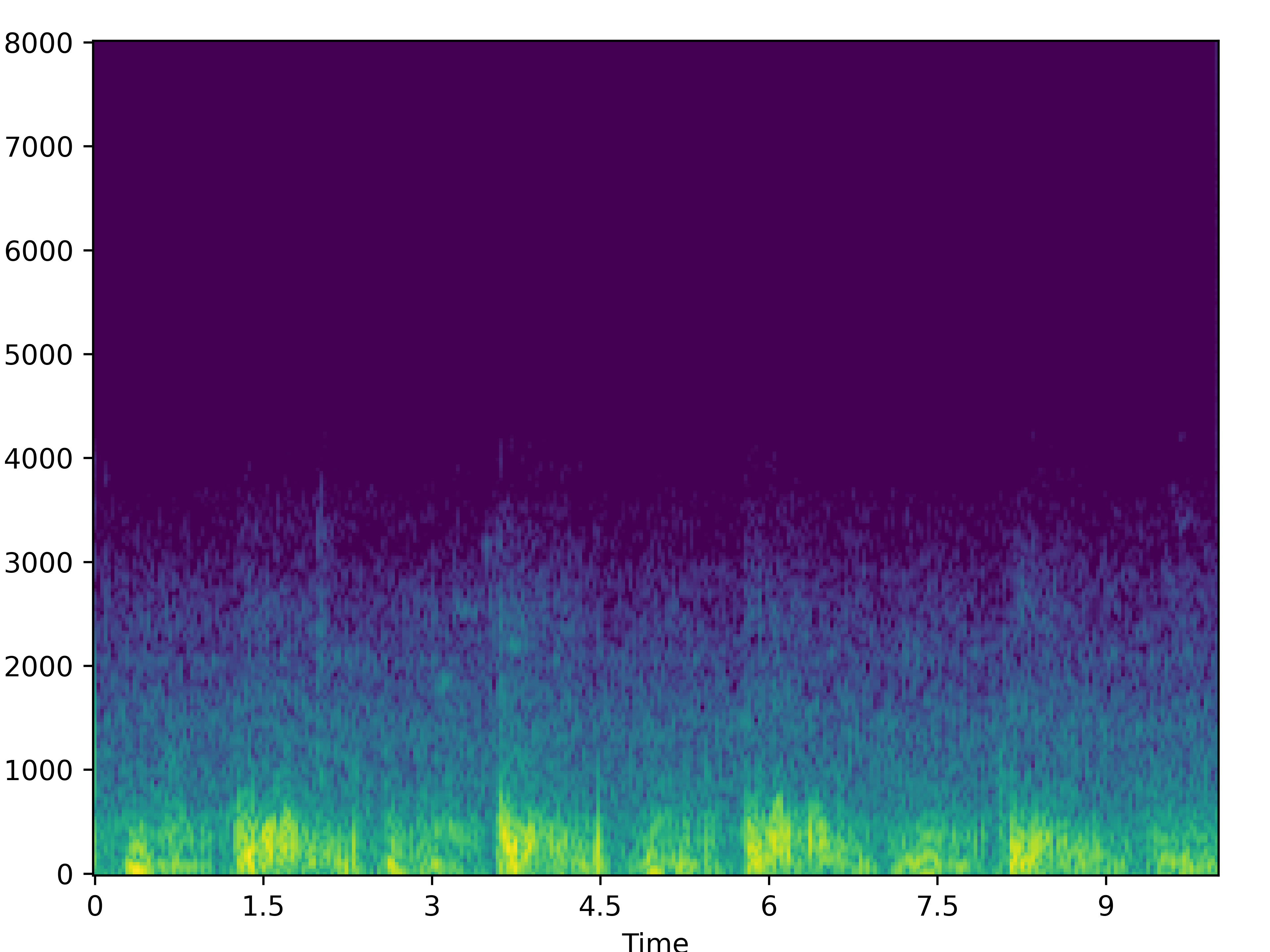 |
Wheezes:
We recommend using headphones for this section.
| Noisy | Wave-U-Net | PHASEN | MANNER | CMGAN | Target | |
|---|---|---|---|---|---|---|
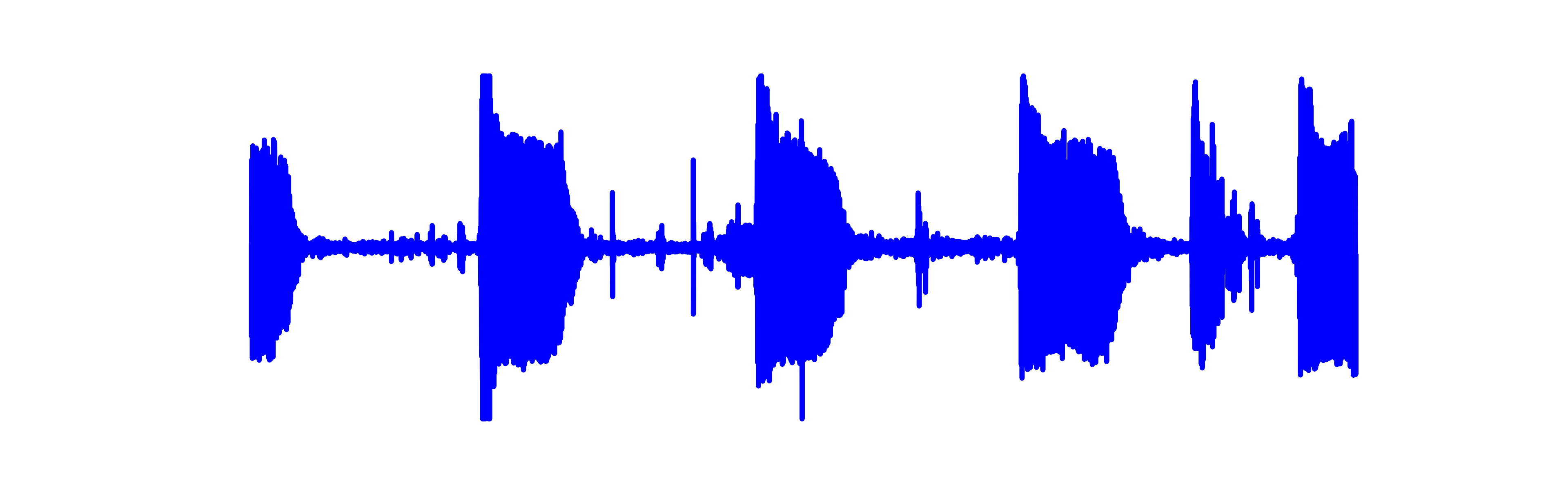 |
 |
 |
 |
 |
 |
|
| 0 |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
| 1 |  |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
| 2 |  |
 |
 |
 |
 |
 |